
Loading...
Loading...
We build production-grade AI: retrieval-augmented generation, task-specific agents, speech/vision pipelines, and robust evaluations—wired to your data with security and observability so results are reliable, safe, and measurable.

From prototypes to governed production systems, built to scale and stay safe.
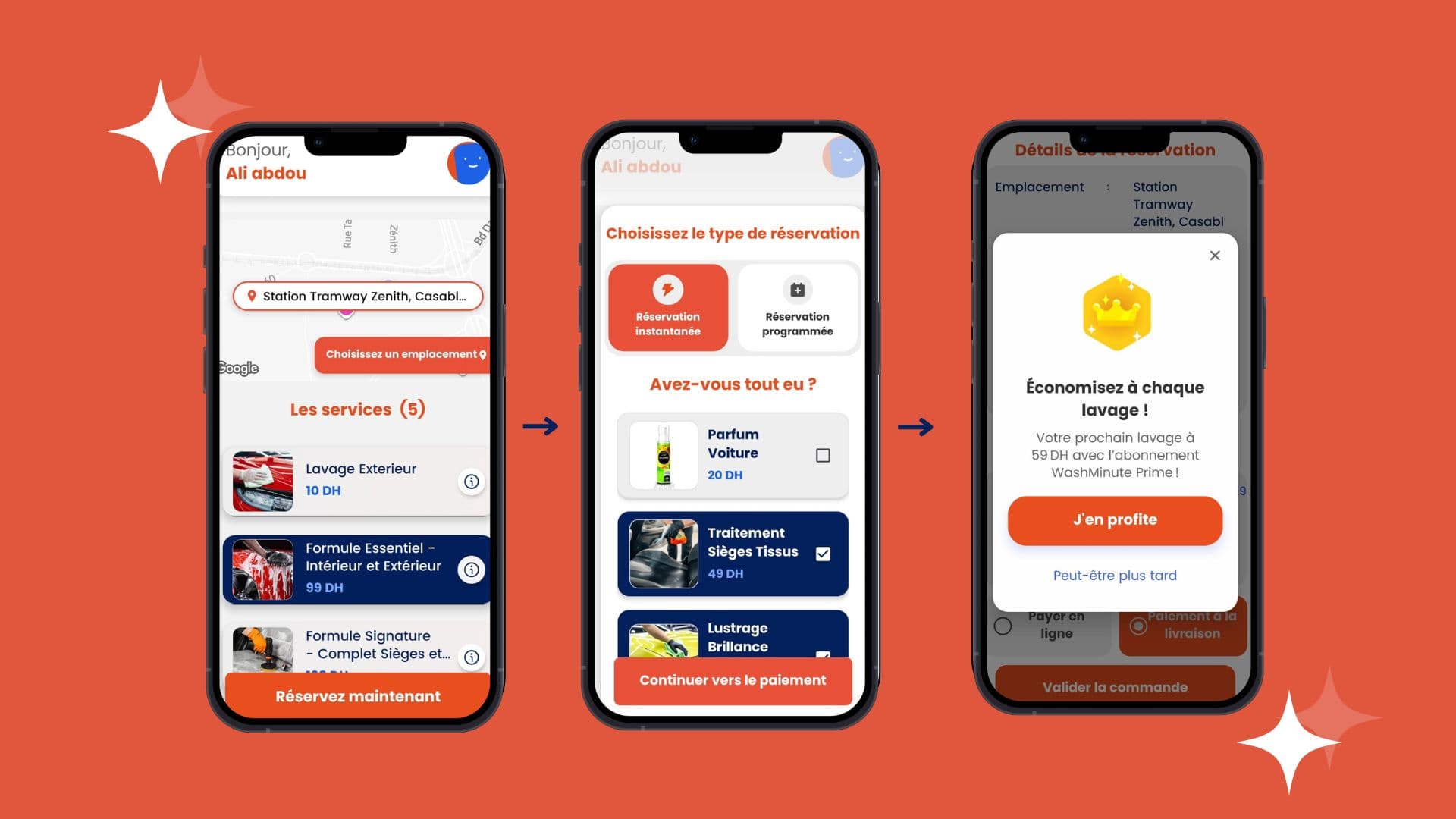
Ground LLMs in your documents & data with hybrid search, chunking, and re-ranking.
Multi-step agents with tools, memory, and guardrails for ops & support.
Golden sets, automatic grading, regression gates, and human-in-the-loop.
PII redaction, toxicity filters, policy checks, and audit trails.
Transcription, TTS, voice bots, OCR, and image understanding.
Instruction tuning, LoRA, and prompt optimization for your domain.
Vector DBs, embeddings, and syncers to keep corpora fresh & relevant.
CRMs, ticketing, ATS, and internal tools with OAuth/SSO & webhooks.
Pipelines, feature stores, CI/CD, monitoring, and cost controls.
Targeted use-cases with measurable KPIs.
Summaries, next-best-actions, and pipeline hygiene.

Agentic bots that read, decide, and execute safely.
Deterministic tool use, retries, and fallbacks with eval gates.
Safety filters, consent, and data retention controls.
Batch & streaming, multi-tenant isolation, cost budgets.
Jobs-to-be-done, risks, KPIs.
Sources, ETL, embeddings, vector schema.
Prompts, tools, and golden sets.
Safety, redaction, and policies.
CI/CD, tracing, cost & quality dashboards.
Feedback loops, AB tests, tuning.
LLM summaries + routing

BI queries in plain English
Automatic evals & human review loops.
Policy enforcement, redaction, and audit.
Feature flags, prompt repos, and OTA configs.
Caching, distillation, and smart routing.
Voice, chat, multimodal, and latency budgets.
CRMs, data lakes, queues, and webhooks.
Open-weight and hosted LLMs; we select per task, latency, cost, and quality.
Yes—VPC/private endpoints, encryption, and no data is used for model training unless you opt-in.
Golden sets, regression evals, dashboards, and periodic human review.
Yes—ASR, TTS, and OCR/vision pipelines with guardrails.
We start with a short discovery and a milestone plan with options.
Yes—SLAs, monitoring, prompt ops, and model/version management.
Let’s align on use-cases, data, safety, and KPIs—then deliver measurable wins.
AI Development
Quick answers to the questions we hear most. Need something specific? Reach out and we will reply within 24 to 48 hours.
Retrieval Augmented Generation lets a language model answer using your private data. If you want an AI assistant that knows your docs, contracts, codebase, or product catalog, you need RAG. We build the retrieval layer, the prompts, and the evaluations so answers stay grounded.
Three layers: grounded retrieval so the model only answers from your sources, citations on every claim so users can verify, and an evaluation harness that tests the system against a curated set of questions before every release. We also build human review queues for high-stakes answers.
We are model-agnostic. We default to Claude Sonnet for production reasoning, Haiku for cheap routing, and OpenAI when a feature needs it. For local or sovereign deployments, we run open weights like Llama or Mistral. We pick based on quality, latency, and your data residency requirements.
Yes. We can deploy entirely on your cloud, use models with zero retention, or run open weights inside your VPC. For Morocco and EU clients we offer EU-region deployments by default. We sign DPAs and never use your data to train shared models.
A focused RAG assistant starts around 25,000 USD and ships in 6 to 10 weeks. A multi-agent system with custom tools and a production evaluation pipeline runs 60,000 to 150,000 USD over 12 to 20 weeks. Inference costs are separate and we help you forecast them.
We do not build to replace people. We build to remove the worst 30 percent of their day, the repetitive lookups, summarization, and triage. Your team keeps judgment work, the agent handles the grind. Clients tell us productivity goes up roughly 2x on the targeted workflow.